


|
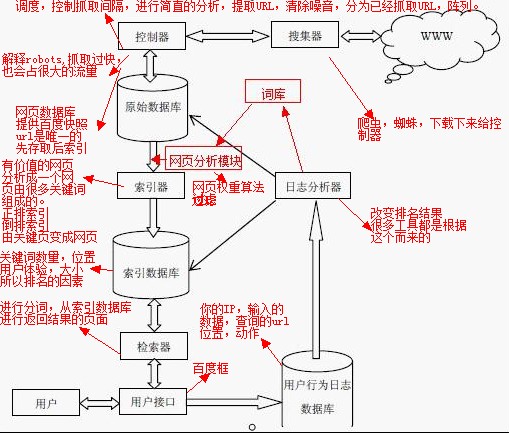
依據上圖解說的查找引擎作業原理,筆者要一步一步為咱們解說引擎優化基礎知識。 1、用戶行動日志數據庫:查找引擎的要點,seo東西和刷排行的軟件都是從這個里邊得出來的。用戶運用查找引擎的進程,和動作; 2、日志剖析器:經過用戶行動日志數據庫進行不斷的剖析,把這些行動記載存儲到索引器傍邊,這些行動會影響排行。也即是咱們所說的歹意點擊,或是一夜排行。(若是經過要害找不到,那么會直接查找域名,這些都將會記入到用戶行動數據庫傍邊); 3、詞庫:頁面剖析模塊中日志剖析器會發現最新的詞匯存入到詞庫傍邊,經過詞庫進行分詞,頁面剖析模塊根據詞庫的。 4、操控器:蜘蛛下載下來的傳給操控器,功用即是調度,比方公交集團的調度室,來操控發車時刻,意圖地,主要來操控蜘蛛的抓取距離,以及派近來的蜘蛛去抓取,咱們做seo的能夠想到,空間方位對seo優化是有利的;
5、原始數據庫:存取頁面的數據庫,即是原始數據庫。存進入即是為了下一步的作業,以及供給baidu快照,咱們會發現,跟md5值相同的url是不重復的,有的url有了,但標題即是沒有,只要經過url這個組件來找到,由于這個沒有經過索引數據庫來樹立索引。原始數據庫主要功用是存入和讀取的速度,以及存取的空間,會經過緊縮,以及為后邊供給效勞。頁面數據庫調度程序將蜘蛛抓取回來的頁面,進行簡略的剖析往后,也即是提取了url,幾乎的過濾鏡像后存入數據傍邊,那么在他的數據傍邊,是沒有樹立索引的; 6、www:咱們的互聯網,一個無窮的、雜亂的系統; 7、收集器:這個咱們站長們就都了解了,咱們對它的俗稱也即是蜘蛛,爬蟲,而他的作業任務即是拜訪頁面,抓取頁面,并下載頁面; 8、頁面剖析模板:這一塊非常重要,查找引擎優化優化的廢物頁面、鏡像頁面的過濾,頁面的權重核算全部都會集在這一塊。稱之為頁面權重算法,幾百個都不止; 9、索引器:把有價值的頁面存入到索引數據庫,意圖即是查詢的速度愈加的快。把有價值的頁面變換別的一個表現形式,把頁面變換為要害字。叫做正排索引,這樣做即是為了便當,頁面有多少個,要害字有多少個。幾百萬個頁面和幾百萬個詞哪一個便當一些。倒排索引把要害字變換為頁面,把排行的條件都存取在這個里邊,現已構成一高效存儲布局,把許多的排行要素作為一個項存儲在這個里邊,一個詞在多少個頁面呈現(一個頁面許多個要害字組成的,把頁面成為要害字這么一個對列進程叫做正排索引。主張索引的緣由:為了便當,進步功率。一個詞在多少個頁面中呈現,把詞成為頁面這么一個對列進程叫做倒排索引。查找成果即是在倒排數據庫幾乎的獲取數據,把許多的排行要素作為一個項,存儲在這個里邊); 10、索引數據庫:將來用于排行的數據。要害字數量,要害字方位,頁面巨細,要害字特征標簽,指向這個頁面(內鏈,外鏈,錨文本),用戶體會這些數據全部都存取在這個里邊,供給給檢索器。為何baidu這么快,即是baidu直接在索引數據庫中供給數據,而不是直接拜訪www。也即是預處理作業; 11、檢索器:將用戶查詢的詞,進行分詞,再進行排序,經過用業界接口把成果回來給用戶。擔任切詞,分詞,查詢,依據排行要素進行數據排序; 12、用戶接口:將查詢記載,ip,時刻,點擊的url,以及url方位,上一次跟下一次點擊的距離時刻存入到用戶行動日志數據庫傍邊。即是baidu的那個框,一個用戶的接口;
|

- 07-19[網站運營] 網站運營,如何做好網站體驗優化
- 05-22[網站運營] 網站分析如何做?
- 03-21[網站運營] [媒體人的一天]新華網李洪雷:網站
- 03-16[人物訪談] 訪談李勇:SEO博客兩個多月快速提
- 02-06[人物訪談] SEO訪談:初入SEO的苦與樂!seo有沒有
- 02-04[自媒體] 內容創業時代來臨:機會、趨勢、
- 01-13[網站運營] 網站運營推廣成功的三大核心問題
- 01-10[自媒體] 內容創業:前景光明還是黑暗?
- 03-16[網站運營] 網站運營之變局-內容為王的時代已



